이 글에서는 프로듀서 애플리케이션에서 카프카 토픽에 메시지를 전송하고 컨슈머는 메시지를 MongoDB에 적재하는 과정을 실습한다.
Docker는 리눅스를 기반으로 하기때문에 윈도우 환경에서 리눅스를 사용할 수 있도록 도와주는 WSL2 ( Windows Subsystem for Linux 2 )를 활성화하고 리눅스 우분투와 도커를 설치 이후 과정을 실습했다.
1. Docker-Compose.yml 작성
도커 컨테이너에 카프카와 주키퍼를 실행하기 위해 Docker-Compose.yml 을 작성한다.
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
ports:
- "2181:2181" # 주키퍼의 기본 포트 2181
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092" # 카프카의 기본 포트 9092
environment: # WSL 2 환경의 IP를 kafka 문자열에 매핑하여 사용했다. 아이피를 직접 입력해도 됨.
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://your_wsl2_ip:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://:9092,OUTSIDE://:9094
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- zookeeper
- KAFKA_ADVERTISED_LISTENERS: INSIDE와 OUTSIDE라는 두 리스너를 정의한다. 이 환경 변수는 클라이언트에게 노출할 브로커의 주소를 지정하는데 INSIDE는 도커 내부 네트워크에서 사용되며, OUTSIDE는 외부에서 브로커에 접근할 수 있도록(WSL2 환경이므로 호스트에서 접근) 사용된다. INSIDE://kafka:9092의 kafka는 로컬 컴퓨터에서 WSL 2에 설치한 카프카 클러스터와 통신할 때 설정한 IP를 사용자 지정 문자로 매핑하여 통신한다.
Windows/System32/drivers/etc/hosts 파일에 아래 줄 추가 your_wsl2_ip kafka - KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 각 리스너의 보안 프로토콜을 정의한다. 리스너는 카프카에서 클라리언트와 브로커 간의 통신을 수신하고 처리하는 역할을 하는데 여기서는 모두 PLAINTEXT로 설정한다. (카프카 클러스터 내에서 클라이언트와 브로커 간의 통신을 암호화하지 않는 보안 프로토콜)
- KAFKA_LISTENERS: 카프카가 수신할 주소와 포트를 정의한다. INSIDE 리스너는 카프카 클러스터 내부 통신용이며, OUTSIDE 리스너는 외부(윈도우 호스트 포함)에서의 접근을 위해 다른 포트(9094)를 사용한다.
- KAFKA_INTER_BROKER_LISTENER_NAME: 카프카 클러스터 내에서 브로커 간 통신을 위한 리스너의 이름을 지정한다.
- KAFKA_ZOOKEEPER_CONNECT: 카프카 브로커가 주키퍼 서버에 연결하는 데 사용되는 주키퍼 연결 문자열을 지정한다.

2. Docker-Compose.yml를 통한 컨테이너 생성
도커 컴포즈 파일이 존재하는 디렉토리에서 아래 명령어를 실행하면 파일 내용의 설정을 기반으로 주키퍼와 카프카 컨테이너를 생성 후 실행한다.
docker-compose up -d // -d 옵션으로 백그라운드에서 실행한다.
3. 도커 컨테이너 상태 확인
토픽 생성 전 카프카 컨테이너 내부로 접근하기 위해 아래 명령어로 도커 컨테이너의 실행 상태를 확인한다.
docker ps
컨테이너 생성 후 실행이 됐다면 STATUS에 Up 으로 출력이 된다

카프카의 IP가 0.0.0.0:9092인 것은 카프카 브로커가 모든 네트워크 인터페이스에서 클라이언트의 연결을 수신할 수 있음을 의미한다. 해당 서버의 모든 네트워크 인터페이스(예: 로컬 호스트, 외부 IP 등)에서 클라이언트의 연결을 수신할 수 있다는 것이다.
4. 카프카 토픽 생성
카프카 클러스터에 토픽을 생성하기 위해 아래 명령어로 카프카 컨테이너 내부에 접근한다.
docker exec -it <container_id_or_name> 892fe61e8e4a /bin/sh
카프카 내부에 접근 후 아래 명령어로 토픽을 생성한다.
kafka-topics.sh --create --bootstrap-server your_broker_ip:9092 --replication-factor 1 --partitions 1 --topic myTopic- kafka-topics.sh: 이 명령어는 카프카 토픽 관리 도구를 실행하는 스크립트이다. 이를 사용하여 카프카 토픽을 생성하거나 관리할 수 있습니다.
- --create: 이 옵션은 새로운 토픽을 생성한다는 것을 나타낸다.
- --bootstrap-server: 이 옵션은 토픽을 생성할 때 사용할 카프카 클러스터의 부트스트랩 서버를 지정한다. 브로커의 ip와 포트를 입력한다.
- --replication-factor: 이 옵션은 토픽의 복제 팩터를 지정한다. 복제 팩터는 토픽의 각 파티션을 복제할 브로커의 수를 의미한다. 이 경우 복제 팩터가 1이므로 각 파티션은 하나의 브로커에만 저장된다.
- --partitions: 이 옵션은 토픽의 파티션 수를 지정한다. 파티션은 토픽의 데이터를 병렬로 처리하기 위해 사용된다. 이 경우 파티션 수가 1이므로 토픽은 하나의 파티션으로만 구성된다.
- --topic: 이 옵션은 생성할 토픽의 이름을 지정한다. 여기서 myTopic은 새로 생성될 토픽의 이름이다.

5. 카프카 토픽에 메시지 전송
토픽에 메시지를 전송을 하기 위해 프로듀서 애플리케이션을 Rest API를 개발한다.
application.yml
server:
port: 9090
spring:
kafka:
producer:
bootstrap-servers: kafka:9092 # WSL 2 환경의 IP를 kafka 문자열에 매핑하여 사용했다. 아이피를 직접 입력해도 됨.
acks: all
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
## 필수옵션 ##
# bootstrap-servers: 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 호스트 이름:포트를 1개 이상 작성한다.
# key-serializer: 레코드의 메시지 키를 직렬화하는 클래스를 지정한다.
# value-serializer: 레코드의 메시지 값을 직렬화하는 클래스를 지정한다.
## 선택 옵션 ##
# acks: 프로듀서가 전송한 데이터가 브로커들에 정상적으로 저장되었는지 전송 성공 여부를 확인하는데 사용하는 옵션.
# 0, 1, -1(all)중 하나로 설정할 수 있다. 설정 값에 따라 데이터의 유실 가능성이 달라진다.
# 1: 리더 파티션에 데이터가 저장되면 전송 성공으로 판단한다. (기본 값 1)
# 0: 프로듀서가 전송한 즉시 브로커에 데이터 저장 여부와 상관 없이 성공으로 판단한다.
# -1: 토픽의 min.insync.replicas 개수에 해당하는 리더 파티션과 팔로워 파티션에 데이터가 저장되면 성공하는 것으로 판단한다.
# buffer.memory: 브로커가 전송할 데이터를 배치로 모으기 위해 설정할 버퍼 메로리 양을 지정한다. (기본 값 32MB)
# retries: 프로듀서가 브로커로부터 에러를 받고 난 뒤 재전송을 시도하는 횟수를 지정한다. (기본 값 2147483647)
# batch.size: 배치로 전송할 레코드 최대 용량을 지정한다. (기본 값 16384)
# 너무 작게 설정하면 프로듀서가 브로커로 더 자주보내기 때문에 네트워크 부담이 있고 너무 크면 메모리를 많이 사용하게 된다.
# linger.ms: 배치를 전송하기 전까지 기다리는 최소 시간이다. (기본 값 0)
# partitioner.class: 레코드를 파티션에 전송할 때 적용하는 파티셔너 클래스를 지정한다. (기본 값 org.apache.kafka.clients.producer.internals.DefaultPartitioner)
# enable.idemotence: 멱등성 프로듀서로 동작할지 여부를 설정한다. (기본 값 false)
# transactional.id: 프로듀서가 레코드를 전송할 때 레코드를 트랜잭션 단위로 묶을지 여부를 설정한다. (기본 값 null)
# 프로듀서의 고유한 트랜잭션 아이디를 설정할 수 있다. 이 값을 설정하면 트랜잭션 프로듀서로 동작한다.
Controller
클라이언트로부터 /api/messages/send 엔드포인트로 POST 요청을 받으면 그 요청의 body에 포함된 메시지(MessageDto 객체)를 Kafka로 전송하기 위해 KafkaProducerService의 sendMessage 메서드를 호출한다.
package com.theyim.kafka.producer.Controlller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.theyim.kafka.producer.dto.MessageDto;
import com.theyim.kafka.producer.service.KafkaProducerService;
@RestController
@RequestMapping("/api/messages")
public class MessageController {
@Autowired
private KafkaProducerService kafkaProducerService;
@PostMapping("/send")
public void sendMessage(@RequestBody MessageDto message) {
kafkaProducerService.sendMessage(message);
}
}
Service
MessageDto 객체를 Kafka의 지정된 토픽("my-topic")으로 전송하기 위해 KafkaTemplate는 메시지를 비동기로 보낼 수 있는 기능을 제공하는 클래스다. 해당 클래스의 send() 메서드를 사용하여 Kafka의 "my-topic" 토픽으로 MessageDto 객체를 전송한다.
package com.theyim.kafka.producer.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import com.theyim.kafka.producer.dto.MessageDto;
@Service
public class KafkaProducerService {
private static String TOPIC_NAME = "my-topic";
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
public void sendMessage(MessageDto messageDto) {
this.kafkaTemplate.send("my-topic", messageDto);
}
}
Postman에서 요청을 보낸 후 아래 명령어로 토픽에 전송된 메시지를 확인한다.
kafka-console-consumer.sh --bootstrap-server kafka_broker_ip:9092 --topic my-topic --from-beginning
6. 컨슈머 애플리케이션 개발
application.yml
프로듀서 애플리케이션의 application.yml 파일에 consumer를 추가한다.
server:
port: 9090
spring:
kafka:
producer:
bootstrap-servers: kafka:9092 # WSL 2 환경의 IP를 kafka 문자열에 매핑하여 사용했다. 아이피를 직접 입력해도 됨.
acks: all
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 메시지 키 직렬화 방식
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 메시지 값 직렬화 방식
consumer:
bootstrap-servers: kafka:9092
group-id: my-consumer-group
auto-offset-reset: earliest
properties:
schema.registry.url: http://kafka:8081
data:
mongodb:
uri: mongodb://localhost:27017/mydatabase # 데이터베이스가 없는 경우 자동으로 생성해준다.
Model
MongoDB에 저장할 메시지 객체를 정의한다.
package com.theyim.kafka.consumer.model;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import lombok.Data;
@Document
@Data
public class Message {
@Id
private String id;
private String name;
private int age;
}
Service
@KafkaListener 어노테이션은 스프링 프레임워크의 일부인 Spring Kafka에서 제공하는 어노테이션으로 특정 Kafka 토픽의 메시지를 자동으로 수신하여 처리할 수 있게 해준다. 메시지가 해당 토픽에 도착할 때마다 스프링이 자동으로 해당 메서드를 호출하여 메시지를 처리할 수 있다.
package com.theyim.kafka.consumer.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.theyim.kafka.consumer.model.Message;
import com.theyim.kafka.consumer.repository.KafkaConsumerRepository;
import lombok.extern.slf4j.Slf4j;
@Service
@Slf4j
public class KafkaConsumerService {
@Autowired
private KafkaConsumerRepository kafkaConsumerRepository;
private final ObjectMapper objectMapper = new ObjectMapper();
// 카프카 클러스터의 토픽 이름과 application.yml의 consumer에 정의된 group-id 입력
@KafkaListener(topics = "my-topic", groupId = "my-consumer-group")
public void lister(String message) {
try {
Message msg = objectMapper.readValue(message, Message.class); // JSON 데이터를 Java 객체로 역직렬화
kafkaConsumerRepository.save(msg);
log.info("성공 " + message);
} catch (Exception e) {
log.error("실패 " + message);
}
}
}
Repository
MongoDB와 연동하기 위해 MongoRepository를 상속받고 값의 타입과 key의 자료형의 제네릭을 지정한다.
package com.theyim.kafka.consumer.repository;
import org.springframework.data.mongodb.repository.MongoRepository;
import com.theyim.kafka.consumer.model.Message;
public interface KafkaConsumerRepository extends MongoRepository<Message, Object> {
}
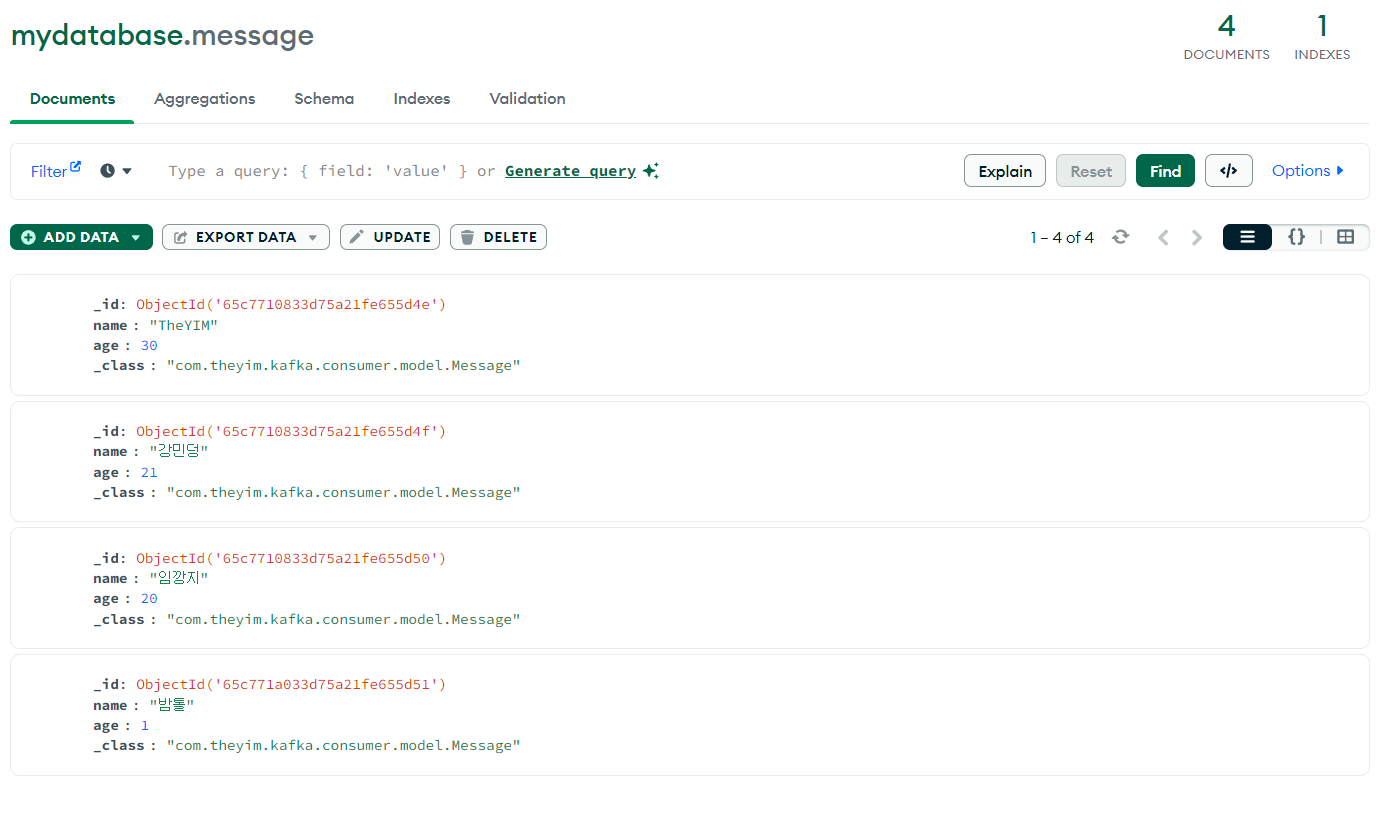
7. 카프카 토픽과 MongDB 메시지 적재 확인
프로듀서에서 전송한 카프카 토픽(토픽명: my-topic)에 실시간으로 메시지가 적재된다.

토픽에 메시지가 적재될 때마다 컨슈머가 자동으로 메서드를 호출하여 메시지를 MongoDB에 적재한다.
'Kafka' 카테고리의 다른 글
| consumer와 partition 의 비율 (0) | 2024.02.17 |
|---|---|
| 카프카(Kafka)의 기본 개념 (0) | 2024.02.11 |

